In this blog post, we will try to predict text in context to a Harry Potter novel.
In text prediction, we can get a body of texts, extract the vocabulary from it, and then create datasets from that, where we make it phrase the Xs, and the next word in that phrase will be the Ys.
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Embedding, LSTM, Dense, Dropout, Bidirectional
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import Adam
from tensorflow.keras import regularizers
import tensorflow.keras.utils as ku
import tensorflow as tf
import numpy as np
Our sample text is from the Harry Potter books. We’ll create a Python list of sentences from the data and convert all of that to lowercase.
Using the tokenizer, we’ll call fit_on_texts to this corpus of work and it will create the dictionary of words and the overall corpus. This is a key-value pair, with the key being the word, and the value being the token for that word.
data = open('/content/potter.txt').read()
corpus = data.lower().split("\n")
corpus[:10]
["mr. and mrs. dursley, of number four, privet drive, were proud to say that they were perfectly normal, thank you very much. they were the last people you'd expect to be involved in anything strange or mysterious, because they just didn't hold with such nonsense. ",
'mr. dursley was the director of a firm called grunnings, which made drills. he was a big, beefy man with hardly any neck, although he did have a very large mustache. mrs. dursley was thin and blonde and had nearly twice the usual amount of neck, which came in very useful as she spent so much of her time craning over garden fences, spying on the neighbors. the dursleys had a small son called dudley and in their opinion there was no finer boy anywhere. ',
"the dursleys had everything they wanted, but they also had a secret, and their greatest fear was that somebody would discover it. they didn't think they could bear it if anyone found out about the potters. mrs. potter was mrs. dursley's sister, but they hadn't met for several years; in fact, mrs. dursley pretended she didn't have a sister, because her sister and her good-for-nothing husband were as undursleyish as it was possible to be. the dursleys shuddered to think what the neighbors would say if the potters arrived in the street. the dursleys knew that the potters had a small son, too, but they had never even seen him. this boy was another good reason for keeping the potters away; they didn't want dudley mixing with a child like that. ",
'when mr. and mrs. dursley woke up on the dull, gray tuesday our story starts, there was nothing about the cloudy sky outside to suggest that strange and mysterious things would soon be happening all over the country. mr. dursley hummed as he picked out his most boring tie for work, and mrs. dursley gossiped away happily as she wrestled a screaming dudley into his high chair. ',
'none of them noticed a large, tawny owl flutter past the window. ',
'at half past eight, mr. dursley picked up his briefcase, pecked mrs. dursley on the cheek, and tried to kiss dudley good-bye but missed, because dudley was now having a tantrum and throwing his cereal at the walls. "little tyke," chortled mr. dursley as he left the house. he got into his car and backed out of number four\'s drive. ',
"it was on the corner of the street that he noticed the first sign of something peculiar -- a cat reading a map. for a second, mr. dursley didn't realize what he had seen -- then he jerked his head around to look again. there was a tabby cat standing on the corner of privet drive, but there wasn't a map in sight. what could he have been thinking of? it must have been a trick of the light. mr. dursley blinked and stared at the cat. it stared back. as mr. dursley drove around the corner and up the road, he watched the cat in his mirror. it was now reading the sign that said privet drive -- no, looking at the sign; cats couldn't read maps or signs. mr. dursley gave himself a little shake and put the cat out of his mind. as he drove toward town he thought of nothing except a large order of drills he was hoping to get that day. ",
"but on the edge of town, drills were driven out of his mind by something else. as he sat in the usual morning traffic jam, he couldn't help noticing that there seemed to be a lot of strangely dressed people about. people in cloaks. mr. dursley couldn't bear people who dressed in funny clothes -- the getups you saw on young people! he supposed this was some stupid new fashion. he drummed his fingers on the steering wheel and his eyes fell on a huddle of these weirdos standing quite close by. they were whispering excitedly together. mr. dursley was enraged to see that a couple of them weren't young at all; why, that man had to be older than he was, and wearing an emerald-green cloak! the nerve of him! but then it struck mr. dursley that this was probably some silly stunt -- these people were obviously collecting for something... ",
'yes, that would be it. the traffic moved on and a few minutes later, mr. dursley arrived in the grunnings parking lot, his mind back on drills. ',
"mr. dursley always sat with his back to the window in his office on the ninth floor. if he hadn't, he might have found it harder to concentrate on drills that morning. he didn't see the owls swoop ing past in broad daylight, though people down in the street did; they pointed and gazed open- mouthed as owl after owl sped overhead. most of them had never seen an owl even at nighttime. mr. dursley, however, had a perfectly normal, owl-free morning. he yelled at five different people. he made several important telephone calls and shouted a bit more. he was in a very good mood until lunchtime, when he thought he'd stretch his legs and walk across the road to buy himself a bun from the bakery. "]
We then find the total number of words in the corpus by getting the length of its word_index. We add 1 to this to consider out-of-vocabulary variables.
tokenizer = Tokenizer()
tokenizer.fit_on_texts(corpus)
total_words = len(tokenizer.word_index) + 1
Let’s take this corpus and turn it into training data.
Our training Xs will be a Python list called input_sequences. Then for each line in the corpus, we’ll generate a token list using the tokenizer’s texts_to_sequences method. This will convert a line of text into a list of the tokens representing the words.
Then we’ll iterate over this list of tokens and create a number of n_gram_sequence.
# create input sequences using list of tokens
input_sequences = []
for line in corpus:
token_list = tokenizer.texts_to_sequences([line])[0]
for i in range(1, len(token_list)):
n_gram_sequence = token_list[:i+1]
input_sequences.append(n_gram_sequence)
Next, we need to find the length of the longest sentence in the corpus. Then we pad all of the sequences so that they are of the same length. We’ll use padding = pre so as to make it easier to extract the label.
# pad sequences
max_sequence_len = max([len(x) for x in input_sequences])
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre'))
Now we turn the sequences into our Xs (input values) and Ys (labels). All we do is take all except the last character as our X, and the last character as our Y.
# create predictors and label
predictors, label = input_sequences[:,:-1],input_sequences[:,-1]
Now we’ll one-hot-encode our labels as this is really a classification problem, where given a sequence of qords, we can classify from the corpus what the next word would likely be. We use the keras utility function to convert a list into a categorical
label = ku.to_categorical(label, num_classes=total_words)
Now we’ll create a neural network to train it with the data. It’s a Sequential model with an Embedding with 128 dimensions to handle al of our words. Another parameter i.e. the input_length is equal to the length of the longest sentence minus 1 since we cropped off the last word of each sequence to get the label. It also has an Bidirectional LSTM with 150 units. The cell state of the LSTM will carry context along with them. The model also consists of a Dropout and a couple of Dense layers. The output layer is activated by softmax. Since we’re doing a categorical classification, we’ll set the loss to be categorical_crossentropy. We’ll use the adam optimizer.
model = Sequential()
model.add(Embedding(total_words, 128, input_length=max_sequence_len-1))
model.add(Bidirectional(LSTM(150, return_sequences = True)))
model.add(Dropout(0.2))
model.add(LSTM(100))
model.add(Dense(total_words, activation='relu', kernel_regularizer=regularizers.l2(0.01)))
model.add(Dense(total_words, activation='relu', kernel_regularizer=regularizers.l2(0.01)))
model.add(Dense(total_words, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
print(model.summary())
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 201, 128) 772224
_________________________________________________________________
bidirectional_1 (Bidirection (None, 201, 300) 334800
_________________________________________________________________
dropout_1 (Dropout) (None, 201, 300) 0
_________________________________________________________________
lstm_3 (LSTM) (None, 100) 160400
_________________________________________________________________
dense_3 (Dense) (None, 6033) 609333
_________________________________________________________________
dense_4 (Dense) (None, 6033) 36403122
_________________________________________________________________
dense_5 (Dense) (None, 6033) 36403122
=================================================================
Total params: 74,683,001
Trainable params: 74,683,001
Non-trainable params: 0
_________________________________________________________________
None
We will create a callback to stop the training when the model accuracy reaches 85%.
class myCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs={}):
if(logs.get('loss')<0.15):
print("\nReached 85% accuracy so cancelling training!")
self.model.stop_training = True
callbacks = myCallback()
history = model.fit(predictors, label, epochs=30, verbose=1, callbacks=[callbacks])
Epoch 1/30
2339/2339 [==============================] - 214s 92ms/step - loss: 4.7067 - accuracy: 0.1652
Epoch 2/30
2339/2339 [==============================] - 214s 91ms/step - loss: 4.6510 - accuracy: 0.1694
Epoch 3/30
2339/2339 [==============================] - 214s 91ms/step - loss: 4.6034 - accuracy: 0.1739
Epoch 4/30
2339/2339 [==============================] - 214s 91ms/step - loss: 4.5633 - accuracy: 0.1779
Epoch 5/30
2339/2339 [==============================] - 214s 91ms/step - loss: 4.5193 - accuracy: 0.1829
Epoch 6/30
2339/2339 [==============================] - 214s 91ms/step - loss: 4.4793 - accuracy: 0.1864
Epoch 7/30
2339/2339 [==============================] - 215s 92ms/step - loss: 4.4420 - accuracy: 0.1910
Epoch 8/30
2339/2339 [==============================] - 215s 92ms/step - loss: 4.4085 - accuracy: 0.1937
Epoch 9/30
2339/2339 [==============================] - 214s 91ms/step - loss: 4.3689 - accuracy: 0.1977
Epoch 10/30
2339/2339 [==============================] - 214s 91ms/step - loss: 4.3406 - accuracy: 0.2008
Epoch 11/30
2339/2339 [==============================] - 214s 92ms/step - loss: 4.3102 - accuracy: 0.2050
Epoch 12/30
2339/2339 [==============================] - 214s 92ms/step - loss: 4.2758 - accuracy: 0.2087
Epoch 13/30
2339/2339 [==============================] - 214s 92ms/step - loss: 4.2498 - accuracy: 0.2120
Epoch 14/30
2339/2339 [==============================] - 214s 92ms/step - loss: 4.2209 - accuracy: 0.2145
Epoch 15/30
2339/2339 [==============================] - 214s 92ms/step - loss: 4.1935 - accuracy: 0.2184
Epoch 16/30
2339/2339 [==============================] - 214s 92ms/step - loss: 4.1677 - accuracy: 0.2203
Epoch 17/30
2339/2339 [==============================] - 214s 92ms/step - loss: 4.1500 - accuracy: 0.2237
Epoch 18/30
2339/2339 [==============================] - 214s 92ms/step - loss: 4.1215 - accuracy: 0.2265
Epoch 19/30
2339/2339 [==============================] - 214s 92ms/step - loss: 4.0961 - accuracy: 0.2289
Epoch 20/30
2339/2339 [==============================] - 214s 92ms/step - loss: 4.0774 - accuracy: 0.2313
Epoch 21/30
2339/2339 [==============================] - 214s 92ms/step - loss: 4.0606 - accuracy: 0.2325
Epoch 22/30
2339/2339 [==============================] - 214s 92ms/step - loss: 4.0427 - accuracy: 0.2352
Epoch 23/30
2339/2339 [==============================] - 214s 92ms/step - loss: 4.0119 - accuracy: 0.2381
Epoch 24/30
2339/2339 [==============================] - 214s 91ms/step - loss: 3.9982 - accuracy: 0.2412
Epoch 25/30
2339/2339 [==============================] - 214s 91ms/step - loss: 3.9759 - accuracy: 0.2456
Epoch 26/30
2339/2339 [==============================] - 214s 91ms/step - loss: 3.9625 - accuracy: 0.2453
Epoch 27/30
2339/2339 [==============================] - 214s 92ms/step - loss: 3.9490 - accuracy: 0.2473
Epoch 28/30
2339/2339 [==============================] - 213s 91ms/step - loss: 3.9250 - accuracy: 0.2499
Epoch 29/30
2339/2339 [==============================] - 214s 92ms/step - loss: 3.9207 - accuracy: 0.2519
Epoch 30/30
2339/2339 [==============================] - 214s 92ms/step - loss: 3.8909 - accuracy: 0.2519
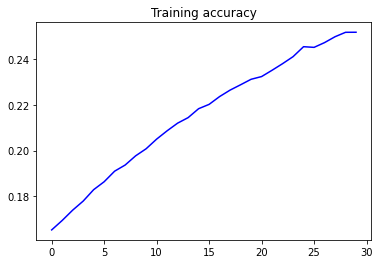
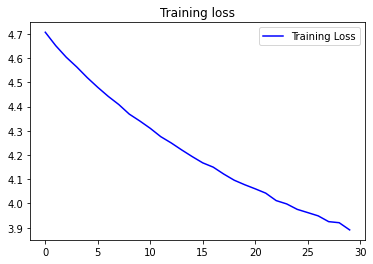
import matplotlib.pyplot as plt
acc = history.history['accuracy']
loss = history.history['loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'b', label='Training accuracy')
plt.title('Training accuracy')
plt.figure()
plt.plot(epochs, loss, 'b', label='Training Loss')
plt.title('Training loss')
plt.legend()
plt.show()
Now for the fun part! Let’s try predicting words using this model that we trained on. We’ll seed it with a text and ask the model for the next 6 words.
What the model is doing is that for each of the next 6 words, it’s going to create token lists using tokenizer text sequences of the seed_text.
seed_text = "Harry was trying out a new spell when"
next_words = 6
for _ in range(next_words):
token_list = tokenizer.texts_to_sequences([seed_text])[0]
token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')
predicted = model.predict_classes(token_list, verbose=0)
output_word = ""
for word, index in tokenizer.word_index.items():
if index == predicted:
output_word = word
break
seed_text += " " + output_word
print(seed_text)
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/sequential.py:450: UserWarning: `model.predict_classes()` is deprecated and will be removed after 2021-01-01. Please use instead:* `np.argmax(model.predict(x), axis=-1)`, if your model does multi-class classification (e.g. if it uses a `softmax` last-layer activation).* `(model.predict(x) > 0.5).astype("int32")`, if your model does binary classification (e.g. if it uses a `sigmoid` last-layer activation).
warnings.warn('`model.predict_classes()` is deprecated and '
Harry was trying out a new spell when he looked into the other room
What we see here is that the sentence predicted does make sense gramatically. But because our dataset is comparatively small and each prediction is a probability, the quality of the prediction is bound to get worse further down the line.